



|
|
|
|
In January I spent a week at this workshop at the Fields Institute in Toronto:
1) Higher Categories and Their Applications, http://math.ucr.edu/home/baez/fields/
It was really fun - lots of people working on n-categories were there. I'll talk about it next time. But as usual, more happens at a fun conference than can possibly be reported. So, this time I'll only talk about a conversation I had in a café before the conference started!
But first, here's a fun way to challenge your math pals:
Q: When the first calculus textbook was written - and in what language?
A: In 1530, in Malayalam - a south Indian language!
This book is called the Ganita Yuktibhasa, or "compendium of astronomical rationales". It was written by Jyesthadeva, an astronomer and mathematician from Kerala - a state on the southwest coast of India. It summarizes and explains the work of many researchers of the Kerala school, which flourished from the 1400's to the 1600's. But it's unique for its time, since it contains proofs of many results.
For example, it has a proof that
π/4 = 1 - 1/3 + 1/5 - 1/7 + 1/9 - ...
Of course, this result isn't stated in modern notation! It's actually stated as a poem - a recipe for the circumference of a circle, which in translation goes something like this:
Multiply the diameter by four. Subtract from it and add to it alternately the quotients obtained by dividing four times the diameter by the odd numbers 3, 5, etc.The proof sounds nice! Jyesthadeva starts with something like this:
π/4 = limN → ∞ (1/N) ∑n=1N 1/(1 + (n/N)2)
In modern terms, the right-hand side is just the integral
∫01 dx/(1 + x2)
You can use geometry to see this equals π/4. Then, as far as I can tell, he writes
1/(1 + (n/N)2) = 1 - (n/N)2 + (n/N)4 - ...
and notes that
1k + 2k + ... + Nk ~ Nk+1/(k+1)
for large N. This gives
π/4 = 1 - 1/3 + 1/5 - 1/7 + ...
Voila!
In fact, this result goes back to Madhava, an amazing mathematician from Kerala who lived much earlier, from 1350 to 1425. What's even more impressive is that Madhava also knew a formula equivalent to the more general result
arctan(x) = x - x3/3 + x5/5 - x7/7 + ...
He used this to compute π to 11 decimal places!
It's an interesting question whether any of the results of the Kerala school found their way west and influenced the development of mathematics in Europe. There's been a lot of speculation, but nobody seems to know for sure. For more info, try these:
2) The MacTutor History of Mathematics Archive, Madhava of Sangamagramma, http://www-history.mcs.st-andrews.ac.uk/Biographies/Madhava.html
3) The MacTutor History of Mathematics Archive, Jyesthadeva, http://www-history.mcs.st-andrews.ac.uk/Biographies/Jyesthadeva.html
4) Wikipedia, Yuktibhasa, http://en.wikipedia.org/wiki/Yuktibhasa
Before the conference started, I spent a nice morning talking with Tom Leinster in a café on Bloor Street. There's nothing like talking about math in a nice warm café when it's cold outside! At some point my former grad student Toby Bartels showed up - he'd just taken a long Greyhound bus from Nebraska - and joined in the conversation. We talked about this paper:
5) Tom Leinster, The Euler characteristic of a category, available as math.CT/0610260.
Everyone know how to measure the size of a set - by its number of elements, or "cardinality". But what's the size of a category? That's the question this paper tackles!
Some categories are just sets in disguise: the "discrete" categories, whose only morphisms are identity morphisms. We'd better define the size of such a category to be the cardinality of its set of objects.
For example, the category with just one object and its identity morphism is called 1. It looks sort of like this:
o
where I've drawn the object but not its identity morphism. Clearly,
its size should be 1.
We could also have a category with just two objects and their identity morphisms. It looks like this:
o o
and its size should be 2.
But what about this?
o--<--->--o
Here we have a category with two objects and an invertible morphism
between them, which I've drawn as an arrow pointing both ways. Again,
I won't draw the identity morphisms.
In other words, we have two objects that are isomorphic - and in a unique way. How big should this category be?
Any mathematician worth her salt knows that having two things that are isomorphic in a unique way is just like having one: you can't do anything more with them - or less. So, the size of this category:
o--<--->--o
should equal the size of this one:
o
namely, 1.
More technically, we say these categories are "equivalent". We'll demand that equivalent categories have the same size. This is a powerful principle. If we didn't insist on this, we'd be insane.
But what about this category:
o---->----o
Now we have two objects and a morphism going just one way!
This is not equivalent to a discrete category, so we need
a new idea to define its size.
If we were willing to make up new kinds of numbers, we could make up a new number for the size of this category. But let's suppose that this is against the rules.
There's a cute way to turn any category into a space, which I described in "week70" - and in more detail in items J and K of "week117", back when I was giving a minicourse on homotopy theory. If we do this to the category
o---->----o
what do we get? The unit interval, of course! It's a pretty
intuitive notion, at least in this example.
We also get the unit interval if we turn this guy
o--<--->--o
into a space. So, even though these categories aren't equivalent,
they give the same space. So, let's declare that they have the
same size - namely, 1.
In fact, let's adopt this as a new principle! We'll demand that two categories have the same size whenever they give the same space.
Whenever categories are equivalent, they give the same space (where "the same" means "homotopy equivalent"). So, our new principle includes our previous principle as a special case. But, we can say more. If you like adjoint functors, you'll enjoy this: whenever there's a pair of adjoint functors going between two categories, they give the same space. For example, these categories
o---->----o
and
o--<--->--o
aren't equivalent, but there's a pair of adjoint functors going between
them. (If you don't like adjoint functors, oh well - just ignore this.)
Next, what's the size of this category?
---->----
/ \
o o
\ /
---->----
This is my feeble attempt to draw a category with two objects, and two
morphisms going from the first object to the second.
If we turn this category into the space, what do we get? The circle, of course! But what's the "size", or "cardinality", of a circle?
That's a tricky puzzle, because it's hard to know what counts as a right answer. It turns out the right answer is zero. Why? Because the "Euler characteristic" of the circle is zero!
As you may know, Euler lived in Königsberg, a city with lots of islands and bridges:
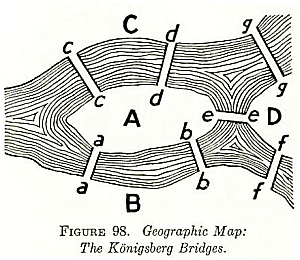
In fact, he published a paper in 1736 showing that you can't walk around Königsberg and cross each bridge exactly once, winding up where you started. My crazy theory is that living there also helped him invent the concept of Euler characteristic. I have no evidence for this, except for this apocryphal story I just made up:
Once upon a time, Euler was strolling along one of the bridges of Königsberg. He looked across the river, and noticed that workers were building a bridge to a small island that had previously been unconnected to the rest. He noticed that this reduced the number of isolated islands by one. Of course, anyone could have seen that! But in a burst of genius, Euler went further - he realized this meant a bridge was like a "negative island". And so, he invented the concept of "Euler characteristic". In its simplest form, it's just the number of islands minus the number of bridges.
For example, if you have two islands in the sea:
o o
the land has Euler characteristic 2.
If you build a bridge:
o---------o
the land now has Euler characteristic 1. This makes sense, because
the land is now effectively just one island. So, a bridge acts as a
"negative island"!
But now, if you build a second bridge:
---------
/ \
o o
\ /
---------
the land has Euler characteristic 0. This is sort of weird. But, Euler
saw it was a good idea.
To understand why, you have to go further and imagine building a "bridge between bridges" - filling in the space between the bridges with an enormous deck:
---------
/xxxxxxxxx\
oxxxxxxxxxxxo
\xxxxxxxxx/
---------
This reduces the number of bridges by one. We've effectively got one
island again, though much bigger now. So, we're back to having Euler
characteristic 1.
In short, adding a "bridge between bridges" should add 1 to the Euler characteristic. Just as a bridge counts as a negative island, a bridge between bridges counts as a negative bridge - or an island:
-(-1) = 1.
It's all consistent, in its own weird way.
So, Euler defined the Euler characteristic to be
V - E + F
where V is the number of islands (or "vertices"), E is the number of bridges (or "edges") and F is the number of bridges between bridges (or "faces").
At least that's how the story goes.
By the way, you must have noticed that the number 1 looks like an interval, while the number 0 looks like a circle. But did you notice that the Euler characteristic of the interval is 1, and the Euler characteristic of the circle is 0? I can never make up my mind whether this is a coincidence or not.
Anyway, we can easily generalize the Euler characteristic to higher dimensions, and define it as an alternating sum. And that turns out to be important for us now, because it turns out that often when we turn a category into a space, we get something higher-dimensional!
This shouldn't be obvious, since I haven't told you the rule for turning a category into a space. You might think we always get something 1-dimensional, built from vertices (objects) and edges (morphisms). But the rule is more subtle. Whenever we have 2 morphisms end to end, like this:
f g
o--->---o--->---o
X Y Z
we can compose them and get a morphism fg going all the way from x to
z. We should draw this morphism too... so the space we get is a
triangle:
Y
o
/x\
f /xxx\ g
/xxxxx\
X o-------o Z
fg
I haven't drawn the arrows on my morphisms, due to technical limitations
of this medium. More importantly, the triangle is filled with x's, just
like Euler's "bridge between bridges", to show that it's
solid, not hollow.
Simlarly, when we have 3 morphisms laid end to end we get a tetrahedron, and so on.
Using these rules, it's not hard to find a category that gives a sphere, or a torus, or an n-holed torus, when you turn it into a space. I'll leave that as a puzzle.
In fact, for any manifold, you can find a category that gives you that manifold when you turn it into a space! In fact we can get any space at all this way, up to "weak homotopy equivalence" - whatever that means. So, let's adopt a new principle: whenever our category gives a space whose Euler characteristic is well-defined, we should define the size of our category to be that.
I say "when it's well-defined", because it's also possible for a category - even one with just finitely many objects and morphisms - to give an infinite-dimensional space whose Euler characteristic is a divergent series:
n0 - n1 + n2 - n3 + n4 - ...
Okay. At this point it's time for me to say what Leinster actually did: he came up with a formula that you can use to compute the size of a category, without using any topology. Sometimes it gives divergent answers - which is no shame: after all, some categories are infinitely big. But when it converges, it satisfies all the principles I've mentioned.
Even better, it works for a lot of categories that give spaces whose Euler chacteristic diverges! For example, we can take any group G and think of it as a category with one object, with the group elements as morphisms. When we turn this category into a space, it becomes something famous called the "classifying space" of G. This is often an infinite-dimensional monstrosity whose Euler characteristic diverges. But, Leinster's formula still works - and it gives
1/|G|
the reciprocal of the usual cardinality of G.
Now we're getting fractions!
For example, suppose we take G to be the group with just 2 elements, called Z/2. If we think of it as a category, and then turn that into a space, we get a huge thing usually called "infinite-dimensional real projective space", or RP∞ for short. This is built from one vertex, one edge, one triangle, and so on. So, if we try to work out its Euler characteristic, we get the divergent series
1 - 1 + 1 - 1 + 1 - ...
But, if we use Leinster's formula, we get 1/2. And that's cute, because once there were heated arguments about the value of
1 - 1 + 1 - 1 + 1 - ...
Some mathematicians said it was 0:
(1 - 1) + (1 - 1) + (1 - 1) + ... = 0
while others said it was 1:
1 + (-1 + 1) + (-1 + 1) + (-1 + 1) + ... = 1
Some said "it's divergent, so forget it!" But others wisely compromised and said it equals 1/2. This can be justified using "Abel summation".
All this may seem weird - and it is; that's part of the fun. But, Leinster's answer matches what you'd expect from the theory of "homotopy cardinality":
6) John Baez, The mysteries of counting: Euler characteristic versus homotopy cardinality, http://math.ucr.edu/home/baez/counting/
This webpage has transparencies of a talk I gave on this, and lots of links to papers that generalize the concepts of cardinality and Euler characteristic. I'm obsessed with this topic. It's really exciting to think about new ways to extend the simplest concepts of math, like counting.
That's why I invented a way to compute the cardinality of a groupoid - a category where every morphism has an inverse, so all the morphisms describe "symmetries". The idea is that the more symmetries an object has, the smaller it is. Applying this to the above example, where our category has one object, and this object has 2 symmetries, one gets 1/2. If this seems strange, try the explanation in "week147".
Later James Dolan took this idea, generalized it to a large class of spaces that don't necessarily come from groupoids, and called the result "homotopy cardinality". We wrote a paper about this.
What Leinster has done is generalize the idea in another direction: from groupoids to categories. The cool thing is that his generalization matches the Euler characteristic of spaces coming from categories (when that's well-defined, without divergent series) and the homotopy cardinality of spaces coming from groupoids (when that's well-defined).
Of course he doesn't call his thing the "size" of a category; he calls it the "Euler characteristic" of a category.
Our conversation over coffee was mainly about me trying to understand the formula he used to define this Euler characteristic. One thing I learned is that the "category algebra" idea plays a key role here.
It's a simple idea. Given a category X, the category algebra C[X] consists of all formal complex linear combinations of morphisms in X. To define the multiplication in this algebra, it's enough to define the product fg whenever f and g are morphisms in our category. If the composite of f and g is defined, we just let fg be this composite. If it's not, we set fg = 0.
Mathematicians seem to be most familiar with the category algebra idea when our category happens to be a group (a category with one object, all of whose morphisms are invertible). Then it's called a "group algebra".
Category algebras are also pretty familiar when our category is a "quiver" (a category formed from a directed graph by freely throwing in formal composites of edges). Then it's called a "quiver algebra". These are really cool - especially if our graph becomes a Dynkin diagram, like this:
o
|
o--o--o--o--o--o--o
when we ignore the directions of the edges. To see what I mean, try
item E in "week230", where I sketch how these quiver algebras are
related to quantum groups. There's a lot more to say about this, but
not today!
In combinatorics, category algebras are familiar when our category is a "partially ordered set", or "poset" for short (a category with at most one morphism from any given object to any other). These category algebras are usually called "incidence algebras".
In physics, Alain Connes has given a nice explanation of how Heisenberg invented "matrix mechanics" when he was trying to understand how atoms jump from one state to another, emitting and absorbing radiation. In modern language, Heisenberg took a groupoid with n objects, each one isomorphic to each other in a unique way. He called the objects "states" of a quantum system, and he called the morphisms "transitions". Then, he formed its category algebra. The result is the algebra of n × n matrices!
(This might seem like a roundabout way to get to n × n matrices, but Heisenberg didn't know about matrices at this time. They weren't part of the math curriculum for physicists back then!)
Connes has generalized the heck out of Heisenberg's idea, studying the "groupoid algebras" of various groupoids.
So, category algebras are all over the place. But for some reason, few people study all these different kinds of category algebra in a unified way - or even realize they're all category algebras! I feel sort of sorry for this neglected concept. That's one reason I was happy to see it plays a role in Leinster's definition of the Euler characteristic for categories.
Suppose our category X is finite. Then, we can define an element of the category algebra C[X] which is just the sum of all the morphisms in X. This is called ζ, or the "zeta function" of our category. Sometimes ζ has an inverse, and then this inverse is called μ, or the "Möbius function" of our category.
Actually, these terms are widely used only when our category is a poset, thanks to the work of Gian-Carlo Rota, who used these ideas in combinatorics:
7) Gian-Carlo Rota, On the foundations of combinatorial theory I: Theory of Möbius Functions, Zeitschrift für Wahrscheinlichkeitstheorie und Verwandte Gebiete 2 (1964), 340-368.
If you want to know what these ideas are good for, check this out:
8) Wikipedia, Incidence algebra, http://en.wikipedia.org/wiki/Incidence_algebra
See the stuff about Euler characteristics in this article? That's a clue! The relation to the Riemann zeta function and its inverse (the original "Möbius function") are clearer here:
9) Wikipedia, Möbius inversion formula, http://en.wikipedia.org/wiki/M%C3%B6bius_inversion_formula
These show up when we think of the whole numbers 1,2,3,... as a poset ordered by divisibility.
Anyway, Leinster has wisely generalized this terminology to more general categories. And when ζ -1 = μ exists, it's really easy to define his Euler characteristic of the category X. You just write μ as a linear combination of morphisms in your category, and sum all the coefficients in this linear combination!
Unfortunately, there are lots of important categories whose zeta function is not invertible: for example, any group other than the trivial group. So, Leinster needs a somewhat more general definition to handle these cases. I don't feel I deeply understand it, but I'll explain it, just for the record.
Besides the category algebra C[X], consisting of linear combinations of morphisms in X, there's also a vector space consisting of linear combinations of objects in X. Heisenberg would probably call this "the space of states", and call C[X] the "algebra of observables", since that's what they were in his applications to quantum physics. Let's do that.
The algebra of observables has an obvious left action on the vector space of states, where a morphism f: x → y acts on x to give y, and it acts on every other object to give 0. In Heisenberg's example, this is precisely how he let the algebra of observables act on states.
The algebra of observables also has an obvious right action on the vector space of states, where f: x → y acts on y to give x, and it acts on every other object to give 0.
Leinster defines a "weighting" on X to be an element w of the vector space of states with
ζ w = 1
Here "1" is the linear combination of objects where all the coefficients equal 1. He also defines a "coweighting" to be an element w* in the vector space of states with
w* ζ = 1
If ζ has an inverse, our category has both a weighting and a coweighting, since we can solve both these equations to find w and w*. But often there will be a weighting and coweighting even when ζ doesn't have an inverse. When both a weighting and coweighting exist, the sum of the coefficients of w equals the sum of coefficients of w* - and this sum is what Leinster takes as the "Euler characteristic" of the category X!
This is a bit subtle, and I don't deeply understand it. But, Leinster proves so many nice theorems about this "Euler characteristic" that it's clearly the right notion of the size of a category - or, with a further generalization he mentions, even an n-category! And, it has nice relationships to other ideas, which are begging to be developed further.
We're still just learning to count.
Addendum: For more discussion, go to the n-Category Café.
© 2006 John Baez
baez@math.removethis.ucr.andthis.edu
|
|
|
|
{kind=link}