
On September 26th, a spacecraft may collide with an asteroid — on purpose! It's a test of whether NASA can deflect an asteroid. With luck it'll change the rock's speed by 0.4 millimeters/second, and noticeably change its orbit around a larger one.
Ten days before impact, the satellite called DART will release a nano-satellite that will watch the collision. Four hours before impact, DART will leave human control and becomes completely autonomous. It'll take its last photo 2 seconds before collision.
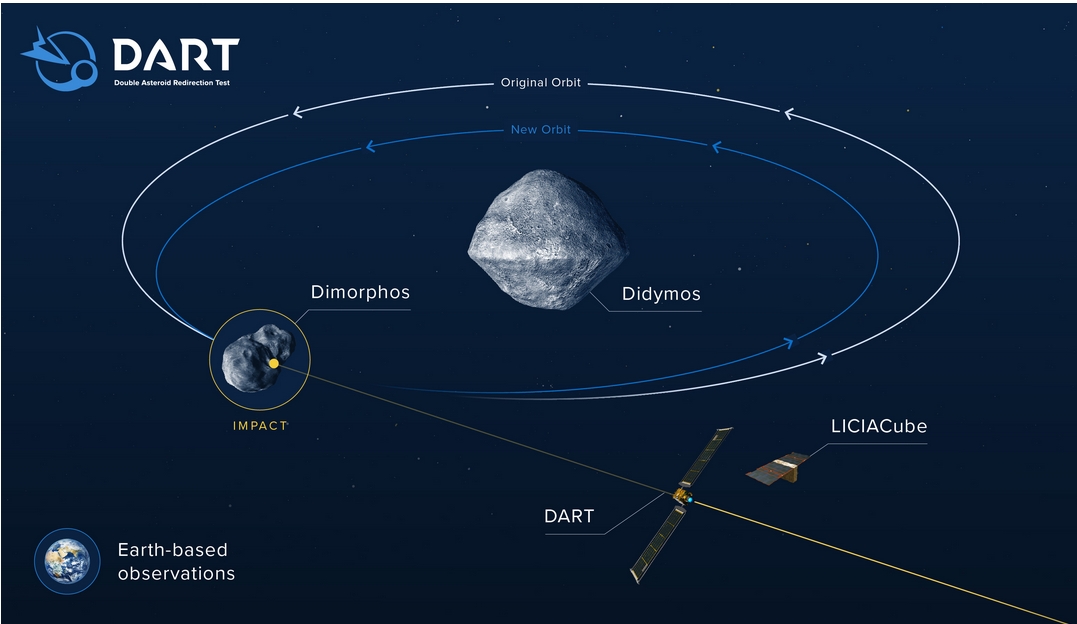
Why hit an asteroid that's orbiting a bigger one? Very smart: this makes it much easier to see the impact's effect! It should change the smaller asteroid's orbital period by 10 minutes — an effect that becomes easy to see after a while.
Why do we need to test this? First, it's not easy to do and we need practice. Second, there is a poorly predictable 'momentum enhancement' effect due to the contribution of recoil momentum from stuff ejected at impact: we need to learn about this!
This mission gives me optimism for what humans can do when we put our minds to it. Maybe I just haven't been paying enough attention, but it seems a bit under-announced. For more:

Entropy is missing information. But we can measure changes in entropy by doing experiments. So if we assume hydrogen has no entropy at absolute zero, we can do experiments to figure out its entropy at room temperature — and see how much information we're missing!
None of this is obvious!
What does "missing information" really mean here?
Why is entropy measured in joules per kelvin?
How do we do experiments to measure changes in entropy?
And why is missing information the same as — or more precisely proportional to — entropy?
The good news: all these questions have answers! And you can learn the answers by studying thermodynamics and statistical mechanics.
However, you have to persist.

I'd like to explain these things, but it won't be quick. When you can calculate the entropy of hydrogen from first principles, and know what it means, that will count as true success.
We'll see how it goes! Partial success is okay too.
July 5, 2022
Before I actually start explaining entropy, a warning:
It can be hard to learn about entropy at first because there are many kinds — and people often don't say which one they're talking about. Here are 5 kinds. Luckily, they are closely related!

In thermodynamics we primarily have a formula for the change in entropy: if you change the internal energy of a system by an infinitesimal amount \(dE\) while keeping it in thermal equilibrium, the infinitesimal change in entropy is \(dS = dE/T\) where \(T\) is the temperature. Rather indirect!
In classical statistical mechanics, Gibbs explained entropy in terms of a probability distribution \(p\) on the space of states of a classical system. In this framework, entropy is the integral of \(-p \ln(p)\) times a constant called Boltzmann's constant.
Later von Neumann generalized Gibbs' formula for entropy from classical to quantum statistical mechanics! He replaced the probability distribution \(p\) by a so-called density matrix \(\rho\), and the integral by a trace.

Here is the simplest link between probability and information:
When you learn that an event of probability p has happened, how much information do you get? We say it's \(-\log p\).
Use whatever base for the logarithm you want; this is like a choice of units. I call \(\log 2\) of information a 'bit' no matter what base I'm using. But when we use logarithms with base 2, \(\log 2 = 1\), which is nice. Then we are measuring information in bits!
We take a logarithm so that when you multiply probabilities, information adds. The minus sign makes information come out positive.
Let's do a few examples to see how this works in practice.
Puzzle 1. First I flip 2 fair coins and tell you the outcome. Then I flip 3 more and tell you the outcome. How much information did you get?
Puzzle 2. I roll a fair 6-sided die and tell you the outcome. Approximately how much information do you get, using logarithms base 2?
Puzzle 3. When you flip 7 fair coins and tell me the outcome, how much information do I get?
Puzzle 4. Every day I eat either a cheese sandwich, a salad, or some fried rice for lunch — each with equal probability. I tell you what I had for lunch today. Approximately how many bits of information do you get?
Puzzle 5. I have a trick coin that always lands heads up. You know this. I flip it 5 times and tell you the outcome. How much information do you receive?
Puzzle 6. I have a trick coin that always lands heads up. You believe it's a fair coin. I flip it 5 times and tell you the outcome. How much information do you receive?
Puzzle 7. I have a trick coin that always lands with the same face up. You know this, but you don't know which face always comes up. I flip it 5 times and tell you the outcome. How much information do you receive?
These puzzles raise some questions about the nature of probability,
like: is it subjective or objective? People like to argue about those
questions. But once we get a probability \(p\), we can convert it to
information by computing \(-\log p\).
July 8, 2022

There are many units of information. Using \( \textrm{information} = - \log p \) we can convert these to probabilities. For example if you see a number in base 10, and each digit shows up with probability 1/10, the amount of information you get from a single digit is one 'hartley'.
Wikipedia has an article that lists many strange units of information. Did you know that 12 bits is a 'slab'? Did you even need to know? No, but now you do.

Feel free to dispose of this unnecessary information! The bit bucket
is out back. All this was just for fun — but I want everyone to
get used to the formula
$$ \textrm{information} = - \log p $$
and realize that different bases for the logarithm give different
units of information. If we use base 2 we're measuring information in
bits; base 16 would be nibbles!
July 9, 2022

How many bits of information does it take to describe a license plate number?
If there are \(N\) different license plate numbers, you need \(\log_2 N\) bits. This is also the information you get when you see a license plate number, if they're all equally likely.
Let's try it out!
Puzzle 1. Suppose a license plate has 7 numbers and/or letters on it. If there are 10+26 choices of number and/or letter, there are \(36^7\) possible license plate numbers. If all license plates are equally likely, what's the information in a license plate number in bits — approximately?

But wait! Suppose you discover that all license plate numbers have a number, then 3 letters, then 3 numbers!
You have just learned a lot of information. So the remaining information content of each license plate is less.
Puzzle 2. About how much information is there in a license plate number if they all have a number, then 3 letters, then 3 numbers? (Assume they're all equally probable and there are 10 choices of each number and 26 choices of each letter.)
The moral: when you learn more about the possible choices, the information it takes to describe a choice drops. You can even use this to figure out how many bits of information you learned: take your original information estimate and subtract the new lower one!
But be careful! When you learn that some of your ideas limiting the possible choices were false, the information it takes to describe a choice can go back up! So, learning your previous theories were false can act like learning 'negative information'.

(It's fun to think about why this isn't true in practice.)
July 11, 2022

The information of an event of probability \(p\) is \(-\log p\), where you get to choose the base of the logarithm.
But why?
This is the only option if we want less probable events to have more information, and information to add for independent events.
Let's prove it!
This will take some math — but you won't need to know this stuff for the rest of my 'course'.
Since we're trying to prove \(I(p)\) is a logarithm function, let's write $$ I(p) = f(\ln(p)) $$ and prove f has to be linear: $$ f(x) = cx. $$ As we'll see, this gets the job done.
Writing \(I(p) = f(x)\) where \(x = \ln p\), we can check that Condition 1 above is equivalent to $$ x \lt y \textrm{ implies } f(x) \gt f(y) \textrm{ for all } x,y \le 0. $$ Similarly, we can check that Condition 2 is equivalent to $$ f(x+y) = f(x) + f(y) \textrm{ for all } x,y \le 0 . $$
Now what functions \(f\) have $$ f(x+y) = f(x) + f(y) $$ for all \(x,y \le 0\)?
If we define \(f(-x) = -f(x)\), \(f\) will become a function from the whole real line to the real numbers, and it will still obey \(f(x+y) = f(x) + f(y)\). So what functions are there like this?
\(f(x+y) = f(x) + f(y)\) is called 'Cauchy's functional equation'. The obvious solutions are $$ f(x) = cx $$ for any real constant c. But are there any other solutions?
Yes, if you use the axiom of choice!
Treat the reals as a vector space over the rationals. Using the axiom of choice, pick a basis. To get \(f \colon \mathbb{R} \to \mathbb{R}\) that's linear over the rational numbers, just let \(f\) send each basis element to whatever real number you want and extend by linearity! This gives a function \(f\) that obeys \(f(x+y) = f(x) + f(y)\).
But no solutions of \(f(x+y) = f(x) + f(y)\) meet our other condition $$ x < y \textrm{ implies } f(x) > f(y) \textrm{ for all } x,y \le 0 $$ except for the familiar ones \(f(x) = cx\). For a proof see Wikipedia: they show all solutions except the familiar ones have graphs that are dense in the plane!
So, our conditions give \(f(x) = cx\) for some c, and since \(f\) is decreasing we need \(c \lt 0\). So our formula $$ I(p) = f(\ln p) $$ says $$ I(p) = c \ln p $$ but this equals \(-\log_b p\) if we take \(b = \exp(-1/c)\). And this number \(b\) can be any number \(\gt 1\).
Done!
So: if we want more general concepts of the information associated to a probability, we need to drop Condition 1 or 2. For example, we could replace additivity by some other rule. People have tried this! It gives a generalization of Shannon entropy called 'Tsallis entropy'.

But I haven't even explained Shannon entropy yet, just the information
associated to an event of probability \(p\). So I'm getting ahead of
myself.
July 12, 2022
You flip a coin. You know the probability that it lands heads up.
How much information do you get, on average, when you discover which
side lands up? It's not hard to work this out. It's a simple example
of 'Shannon entropy'.

Try some examples:
Puzzle 1. Suppose you know a coin lands heads up \(\frac{1}{2}\) of the time and tails up \(\frac{1}{2}\) of the time. The expected amount of information you get from a coin flip is $$ \textstyle{ -\frac{1}{2} \log(\frac{1}{2}) - \frac{1}{2} \log(\frac{1}{2}) } $$ Taking the log base 2 gives you the Shannon entropy in bits. What do you get?
Puzzle 2. Suppose you know a coin lands heads up \(\frac{1}{3}\) of the time and tails up \(\frac{2}{3}\) of the time. The expected amount of information you get from a coin flip is $$ \textstyle{ -\frac{1}{3} \log(\frac{1}{3}) - \frac{2}{3} \log(\frac{2}{3}) } $$ What is this in bits? You can use an online calculator that does logs in base 2.
Puzzle 3. Suppose you know a coin lands heads up \(\frac{1}{4}\) of the time and tails up \(\frac{3}{4}\) of the time. The expected amount of information you get from a coin flip is $$ \textstyle{ -\frac{1}{4} \log(\frac{1}{4}) - \frac{3}{4} \log(\frac{3}{4}) } $$ What is this in bits?
Here's the pattern: the Shannon entropy is biggest when the coin is fair. As it becomes more and more likely for one side to land up than the other, the entropy drops. You're more sure about what will happen... so you learn less, on average, from seeing what happens!
We've been doing examples with just two alternatives: heads up or
down. But you can do Shannon entropy for any number of mutually
exclusive alternatives. It measures how ignorant you are of what will
happen. That is: how much you learn on average when it does!
July 13, 2022

If the weather report tells you it'll rain different amounts with different probabilities, you can figure out the 'expected' amount of rain. You can also figure out the expected amount of information you'll learn when it rains! This is called 'Shannon entropy'.
The Shannon entropy doesn't depend on the amounts of rain, or whether the forecast is about centimeters of rain or dollars of income. It only depends on the probabilities of the various alternatives! So Shannon entropy is a universal, abstract concept.
Entropy was already known in physics. But by lifting entropy to a more general level and connecting it to digital information, Shannon helped jump-start the information age. In fact a paper of his was the first to use the word 'bit'!


I've been leading up to it, but here it is: Shannon entropy!
Gibbs had already used the same formula in physics — with base \(e\) for the logarithm, an integral instead of a sum, and multiplying the answer by Boltzmann's constant.
Shannon applied it to digital information.
July 19, 2022

What's entropy good for? For starters, it gives a principle for choosing the 'best' probability distribution consistent with what you know. Choose the one with the most entropy!
This is the key idea behind 'statistical mechanics' — but we can use it elsewhere too.
You have a die with faces numbered 1,2,3,4,5,6. At first you think it's fair. But then I roll it a bunch of times and tell you the average of the numbers that come up is 5.
What's the probability that if you roll it, a 6 comes up?
Sounds like an unfair question!
But you can figure out the probability distribution on {1,2,3,4,5,6} that maximizes Shannon entropy subject to the constraint that the mean is 5. According to the principle of maximum entropy, you should use this to answer my question!
But is this correct?
The problem is figuring out what 'correct' means!
But in statistical mechanics we use the principle of maximum entropy all the time, and it seems to work well. The brilliance of E. T. Jaynes was to realize it's a general principle of reasoning, not just for physics.

The principle of maximum entropy is widely used outside physics, though still controversial.
But I think we should use it to figure out some basic properties of a gas — like its energy or entropy per molecule, as a function of pressure and temperature.
To do this, we should generalize Shannon entropy to 'Gibbs entropy', replacing the sum by an integral. Or else we should 'discretize' the gas, assuming each molecule has a finite set of states. It sort of depends on whether you prefer calculus or programming. Either approach is okay if we study our gas using classical statistical mechanics.
Quantum statistical mechanics is more accurate. It uses a more general definition of entropy — but the principle of maximum entropy still applies!
I won't dive into any calculations just yet. Before doing a gas, we should do some simpler examples — like the die whose average roll is 5. But I can't resisting mentioning one philosophical point. Here I'm hinting that maximum entropy works when your 'prior' is uniform:

But what if our set of events is something like a line? There's no uniform probability measure on the line! And even good old Lebesgue measure \(dx\) depends on our choice of coordinates. So at this point we should bite the bullet and learn about 'relative entropy'.
In short, a deeper treatment of the principle of maximum entropy pays more attention to our choice of 'prior': what we believe before we learn new facts. And it brings in the concept of 'relative entropy': entropy relative to that prior.
But let's not rush things!
July 22, 2022
A key part of science is admitting our ignorance.
When we describe a situation using probabilities, we shouldn't pretend we know more than we really do. The principle of maximum entropy is a way to make this precise.
Let's see how it works!

Remember: if we describe our knowledge using a probability distribution, its Shannon entropy says how much we expect to learn when we find out what's really going on.
We can roughly say it measures our 'ignorance' — though ordinary language can be misleading here.

At first you think this ordinary 6-sided die is fair. But then you learn that no, the average of the numbers that come up is 5. What are the probabilities \(p_1, \dots, p_n\) for the different faces to come up?
This is tricky: you can imagine different answers that work!
You could guess the die lands with 5 up every time. In other words, \(p_5 = 1\).
This indeed gives the correct average. But the entropy of this probability distribution is 0. So you're claiming to have no ignorance at all of what happens when you roll the die!
Next you guess that it lands with 4 up half the time and 6 up half the time. In other words, \(p_4 = p_6 = \frac{1}{2}\).
This probability distribution has 1 bit of entropy. Now you are admitting more ignorance. Good! But how can you be so sure that 5 never comes up?
Next you guess that \(p_4 = p_6 = \frac{1}{4}\) and \(p_5 = \frac{1}{2}\). We can compute the entropy of this probability distribution. It's higher: 1.5 bits.
Good, you're being more honest now! But how can you be sure that 1, 2, or 3 never come up? You are still pretending to know stuff!
Keep improving your guess, finding probability distributions with mean 5 with bigger and bigger entropy. The bigger the entropy gets, the more you're admitting your ignorance! If you do it right, your guess will converge to the unique maximum-entropy solution.
Or you can use a bit of calculus, called 'Lagrange multipliers', to figure out the maximum-entropy probability distribution with mean 5 without all this guessing! This is very slick.
But today I'm just trying to explain the principle: admit your ignorance.
July 26, 2022
How do you actually use the principle of maximum entropy?
If you know the expected value of some quantity and want to maximize entropy given this, there's a great formula for the probability distribution that does the job!
It's called the 'Gibbs distribution'.

The Gibbs distribution is also called the 'Boltzmann distribution' or 'canonical ensemble', especially when the quantity \(A\) whose expected value you know is energy. In statistics it's also called an 'exponential family'.
In the Gibbs distribution, the probability \(p_i\) is proportional to \(\exp(-\beta A_i)\) where \(A\) is the quantity whose expected value you know. It's easy to find the expected value as a function of the number \(\beta\). The hard part is solving that equation for \(\beta\).
Why does the Gibbs distribution actually work? You want numbers \(p_i\) that maximize entropy subject to two constraints: $$ \sum_i p_i = 1 $$ $$ \sum_i A_i p_i = a $$ This is a calculus problem that succumbs easily to Lagrange multipliers. One of those multipliers, the one that imposes the second constraint, is \(\beta\).
(Try it!)
You can use the Gibbs distribution to solve the puzzle I mentioned last time:
At first you think this ordinary 6-sided die is fair. But then you learn that no, the average of the numbers that come up is 5. What are the probabilities \(p_1, \dots, p_n\) for the different faces to come up? You can use the Gibbs distribution to solve this puzzle!To do it, take \(1 \le i \le 6\) and \(A_i = i\). Stick the Gibbs distribution \(p_i\) into the formula \(\sum_i A_i p_i = 5\) and get a polynomial equation for \(\exp(-\beta)\). You can solve this with a computer and get \(\exp(-\beta) \approx 1.877\).
So, the probability of rolling the die and getting the number \(1 \le i \le 6\) is proportional to \(\exp(-\beta i) \approx 1.877^i\). You can figure out the constant of proportionality by demanding that the probabilities sum to \(1\) (or just look at the formula for the Gibbs distribution). You should get these probabilities: $$ p_1 \approx 0.02053, \; p_2 \approx 0.03854, \; p_3 \approx 0.07232, \; p_4 \approx 0.1357, \; p_5 \approx 0.2548, \; p_6 \approx 0.4781. $$
You can compute the entropy of this probability distribution and you get roughly \(1.97\) bits. You'll remember that last time we got entropies up to 1.5 bits just by making some rather silly guesses.
So, thanks to Gibbs, you can find the maximum-entropy die that rolls 5 on average. And the same math lets us find the maximum-entropy state of a box of gas that has some expected value of energy!
Here is Gibbs himself:

For more, read this:
But what does \(\beta\) mean?
When \(A_i\) is energy, \(\beta\) is the 'coolness'.

When \(\beta\) is big, the probability of being in a state of high energy is tiny, since \(\exp(-\beta A_i)\) gets very small for large energies \(A_i\). This means our system is cold.
States of high energy are more probable when \(\beta\) is small. Then our system is hot.
It turns out \(\beta\) is inversely proportional to the temperature — more about that later. In modern physics \(\beta\) is just as important as temperature. It comes straight from the principle of maximum entropy!
So it deserves a name. And its name is 'coolness'!
For more of my entropy explanations, go to my August 1st diary entry. Now I want to talk about my personal life.
July 28, 2022
I was talking to Todd Trimble and Joe Moeller about mathematics, as usual
on a Thursday morning, when I saw a UPS truck drive up. I ran out and yes,
there were two envelopes, containing Lisa's and my passports with UK visas!
This means we can go to Edinburgh in September.
It's been a fraught process! We originally planned to go there from July
to December: I've got a Leverhulme Fellowship to work with Tom Leinster.
But two months have been chopped off our stay because the visa process
was so slow, including a month of machinations at the University of
Edinburgh. We may try to add those two months to our visit next year,
when we were slated for a second 6-month stay.
July 29, 2022
Recently Lisa and I were doing a bit of yard work in the front yard
when I saw what looked like a rattlesnake near us, coiled up and
preparing to strike. It was silent and very well camouflaged. I
grabbed Lisa and moved her away. We left and all was well.
We get rattlesnakes around here but this put me on edge. I often take the trash out at night barefoot, but now I've started worrying a bit and paying careful attention. The other night I had just done this and was walking back into the garage when I saw a big...
... tarantula on the floor.
Whew! Just a tarantula. For a second there I was really shocked.
But tarantulas, while scary-looking, are not aggressive, and this one
was downright sluggish. I walked around it, went into the house and
closed the door.
July 30, 2022

In 1996, an archaeologist found a pebble in the desert in southwest Egypt amidst a field of Libyan desert glass: sand melted by some sort of impact.

Isotope analyses seem to show that this pebble, now called the Hypatia stone, is not from the Earth — nor from a meteorite or comet, nor from the inner Solar System, nor from typical interstellar dust. Now some argue it's from a supernova!
The best fit is a supernova involving a white dwarf and another star. These make most of the iron in our universe. But isotopes of 6 elements don't match what we expect from such a supernova. So I'd say we're not done with this mystery!
There are difficulties in analyzing this stone, since it's small and full of tiny cracks filled with clay. But it's been chopped into pieces and analyzed with a lot of high-tech equipment by different teams. The new paper explains it quite well:

It's fun to think that maybe dust ejected from a type Ia supernova formed this stone and eventually landed in Egypt! The guy who picked it up, Aly A. Barakat, was very observant and lucky.